Best Practices for Function Calling in LLMs in 2025
This blog is for developers, engineers, product managers, technical leaders, AI researchers and architects, enterprises, startups, and AI enthusiasts.
If you’re new to AI, we suggest reading The Beginner's Guide to AI Models: Understanding the Basics and In-Depth Study of Large Language Models (LLM) to understand the contents of this article better.
TL;DR
- Function calling is the bridge from conversation to action, letting LLMs use real-world tools and APIs.
- The LLM acts as a translator, converting user requests into structured JSON commands for your application to execute.
- This unlocks powerful use cases like live data retrieval, workflow automation, and multi-step reasoning.
- It introduces major technical hurdles in language ambiguity, schema complexity, and performance latency.
- Security is the most critical risk, with prompt injection attacks posing a severe threat to your data and systems.
- Success demands disciplined engineering with clear schemas, smart orchestration patterns, and robust feedback loops.
- The future is standardization around JSON Schema to solve today's messy M x N integration problem.
- This is the foundational step towards creating and orchestrating complex, autonomous agent ecosystems.
Introduction to Function Calling
Since their inception, Large Language Models have been the poster child for the next generation of technology. Stalwarts of the AI world, including Sam Altman, Satya Nadella, Sundar Pichai, Elon Musk, etc., point to how they are redefining work.
As brilliant and eloquent as LLMs are, they used to be utterly powerless. They were digital oracles, trapped within the confines of their training data, like a static snapshot of the past. An LLM could write a poem about rain, but it couldn't tell you the current weather. This fundamental gap between conversation and action limited AI’s true potential.
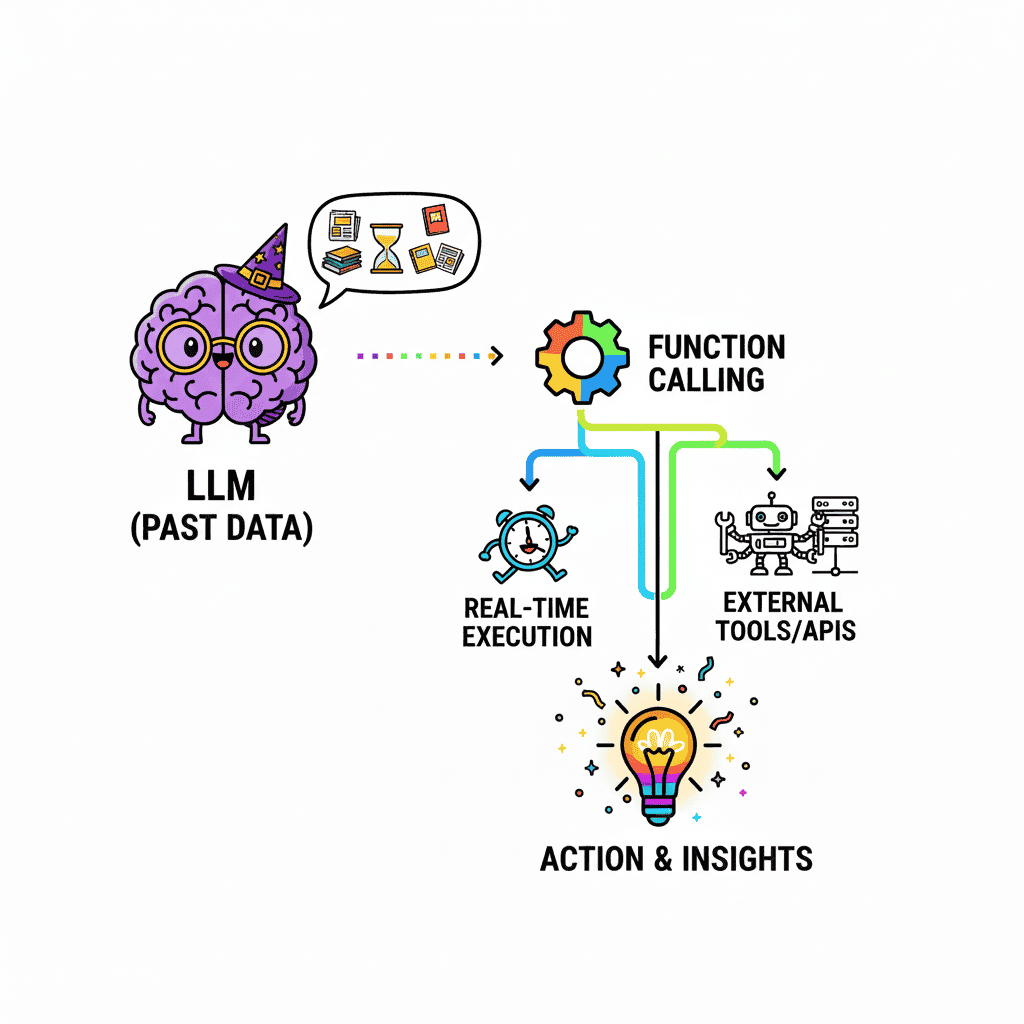
How Function Calling Empowers LLMs
Enter Function Calling. This isn't just another feature; it's the bridge that finally connects the immense reasoning power of LLMs to the real, functional world of APIs, databases, and external tools. Tool calling is an evolutionary leap that transforms LLMs from know-it-alls into do-it-alls, allowing them to execute tasks, fetch live data, and interact with systems on a user's behalf.
But this newfound power introduces a new layer of complexity. The line between a seamless, intelligent agent and a clumsy, error-prone bot is razor-thin, and it is drawn by the proper implementation of function calls.
In this blog, we'll dissect function calling. We'll explore what function calling is and how its intricate mechanism works. This blog also highlights the common limitations one might face while using function calling and how Cognis Ai helps overcome these complexities.
Fundamentals of Function Calling
What is Function Calling?
At its core, function calling gives the 'brain-in-a-jar' LLM a toolkit and a direct line to the outside world. It is the structured protocol that allows the model to translate your natural language request into a precise, machine-readable command for an external tool or API. This is the mechanism that finally gives your AI the ability to act.
Crucially, the LLM itself doesn't execute the function. It acts as a translator, converting your intent into a structured JSON command with the correct function name and arguments. Your application receives this command and performs the actual execution. This delegation creates a secure barrier, ensuring the LLM directs the action without running the underlying code itself.
This process mirrors traditional software development. The LLM's output isn't the function itself. It is a structured request to run one. Think of it as an intelligent API call. The model dynamically chooses the right endpoint. It also extracts the necessary parameters from your prompt. This creates a natural language front-end for your existing code and APIs.
How LLMs Handle Function Calls
So how does this process actually work? It is not a single, magical step. It is a structured dance between the LLM and your application code. This workflow ensures the model can reason about actions without executing them directly.'
- Tool Definition: First, developers define the available tools for the LLM. They provide a structured schema for each function. This schema explains the tool's purpose. It also lists the required parameters for the model to use.
- Request & Decision: The user requests natural language. The LLM analyzes this input. It decides if a tool is needed to answer. If yes, it generates a JSON object with the correct function name and arguments.
- External Execution: Your application receives the JSON command from the model. It is responsible for running the actual code. The LLM does not execute the function. Your system calls the API or database and captures the result.
- Final Answer Generation: The function's result is sent back to the LLM. The model uses this new information as context. It then generates a final, coherent language response for the user, completing the entire request.
Key Takeaway: The LLM is the brain that decides what to do. Your application provides the hands to actually do it.
Example: User asks ➔ LLM translates to a command ➔ Your app executes it ➔ The LLM provides the final answer.

Example of Function Calling in LLMs
Architecture of Function Calling in LLMs
The entire function calling process relies on three core pillars. Each part plays a critical and distinct role in the workflow. Let's break down these essential components.
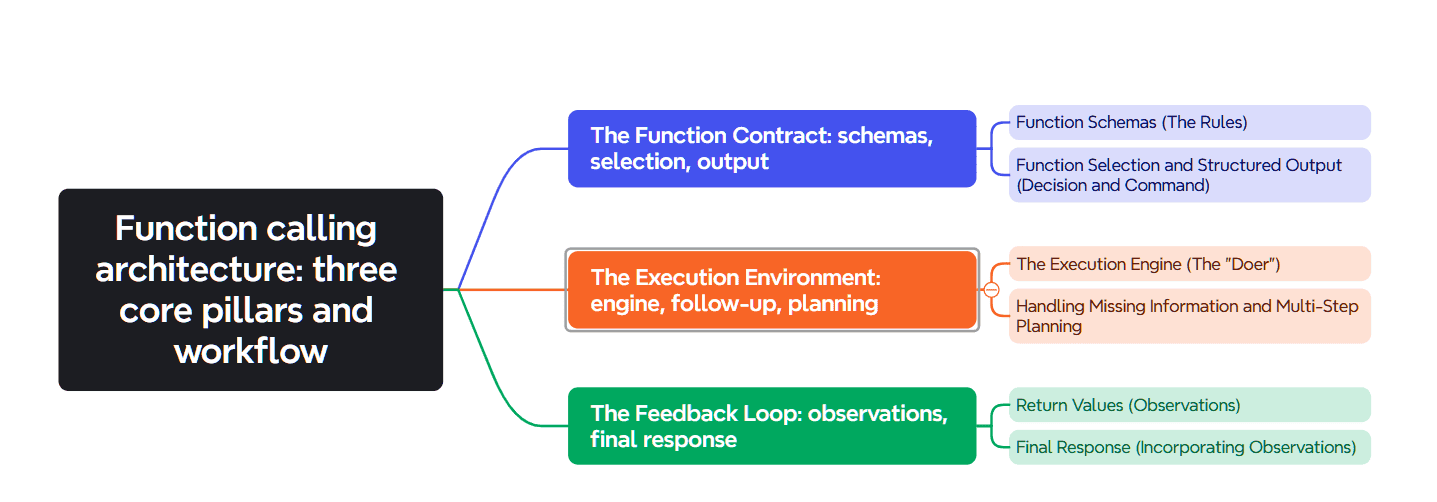
Key Components in the Architecture of Function Calling
1. Function Schemas (The Rules)
Schemas are the non-negotiable rulebook for the LLM. They act as a stable contract. This contract defines each tool's unique name. It clearly describes its purpose. It also details all required parameters and their data types. Providing good examples in the schema often leads to better, more reliable outputs.
2. Function Selection (The Decision)
The LLM must autonomously make three critical choices. Should it use a tool? Which one? And how? It matches user intent to function descriptions. This helps it decide the correct action. The ability to detect when no tool is needed is a crucial test of its relevance detection.
3. Structured Output (The Command)
When the LLM decides to act, it acts decisively. It generates a structured function call. This is typically a JSON object. This output includes the chosen function name. It also contains the specific arguments or parameters. These are extracted directly from the user's natural language request.
⭐Case Study: Ordering Pizza for your dog Captain Floof
Your Prompt: ‘Order a tiny pizza for Captain Floof.’ The LLM sees its order_pizza function. The schema requires size and toppings. The model correctly generates the command. It sets toppings to ‘sunflower seeds and cheese’.
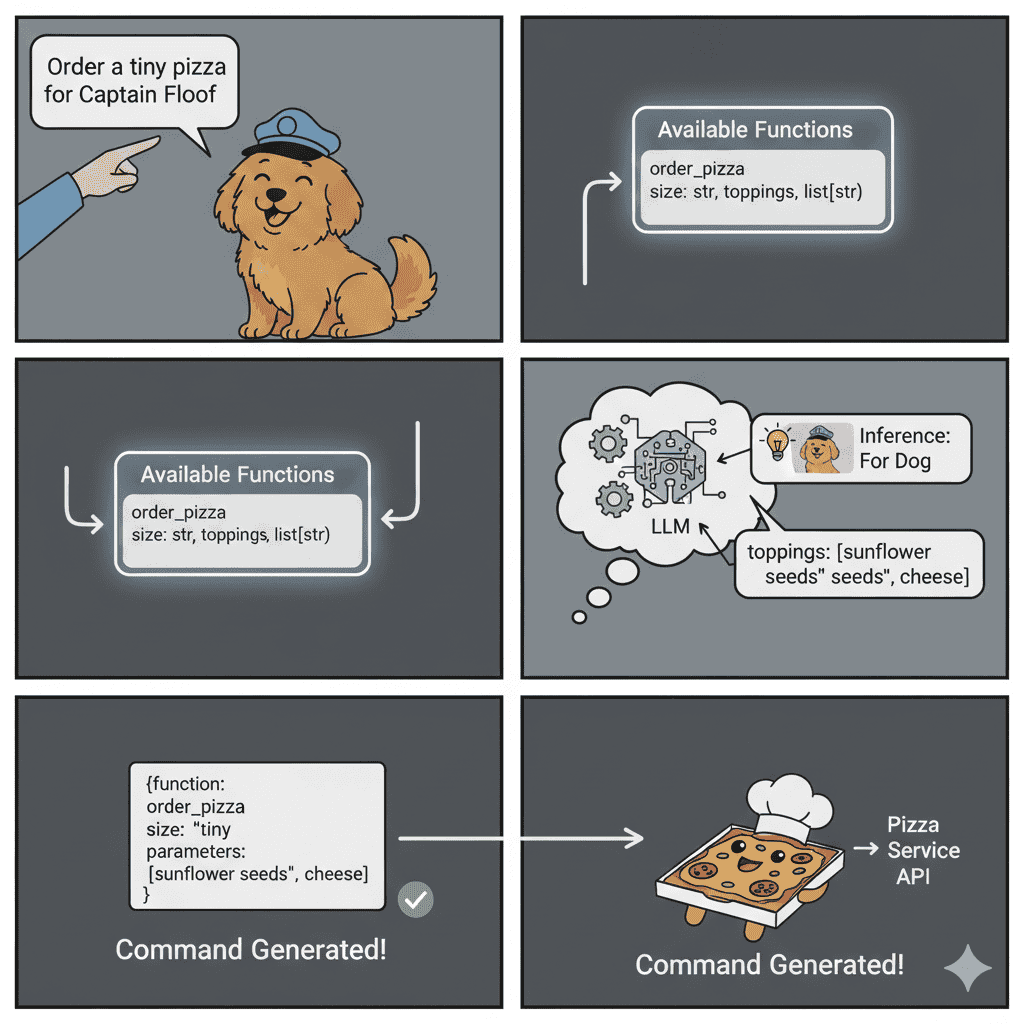
The Function Contract - Case Study
4. The Execution Engine (The ‘Doer’)
The LLM does not run the code itself. An external engine must execute the action. This engine receives the LLM's command. It then runs the corresponding tool script safely. For robust agentic systems, this environment can be structured to handle complex computational tasks or search functions.
5. Handling Missing Information (The Follow-up)
What if a query is missing critical details? The system must recognize this information gap. It cannot guess or fail silently. Instead, the model is expected to generate a natural language response. It should ask the user a clear follow-up question to get the needed parameters.
6. Multi-Step Planning (The Workflow)
Function calling enables complex, multi-turn workflows. It uses an iterative, multi-step process. The core loop is: Thought, Action, Observation. This allows for advanced planning and execution. More sophisticated systems can even use control flows. This includes logic like IF-ELSE statements or loops for tasks.
⭐Case Study: Ordering Pizza for your dog Captain Floof
The pizza shop's API receives the weird order. It has a problem with size: tiny. The smallest size is 'personal'. The system also lacks a delivery address. This is a classic case of missing info. Execution pauses.
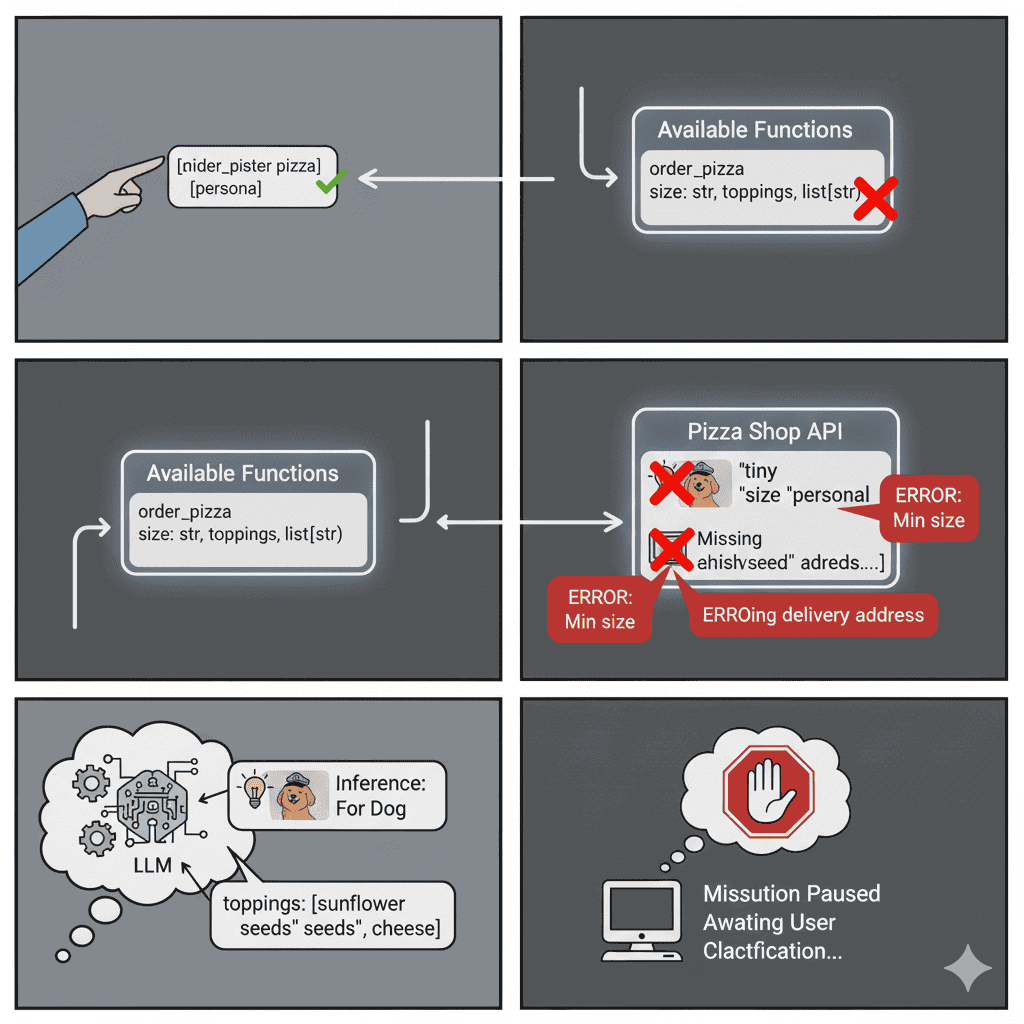
The Execution Environment - Case Study
7. Return Values (The Observation)
After the external system executes the action, its result is sent back. The returned data is called the Observation. It must be transformed into a simple format, like text. This observation grounds the LLM's final answer in real-world data, providing crucial context for its final response.
8. Final Response (The Synthesis)
The LLM receives the Observation data. It fully incorporates this new context into its reasoning. This is the final ‘Thought’ step. Using the retrieved, real-world data, it generates the final answer. This synthesized response is coherent, contextual, and directly addresses the user's original prompt with accuracy.
⭐Case Study: Ordering Pizza for your dog Captain Floof
The API returns an error: Invalid size.
It also notes: Address required.
This ‘Observation’ is sent to the LLM. The LLM then synthesizes a polite response. It asks you for the correct size by listing available sizes and also for Captain Floof's full home address for delivery.

The Feedback Loop - Case Study
Error Handling and Guardrails
Connecting a creative LLM to real-world tools is powerful. It is also incredibly dangerous. Without strict controls, systems can fail, costs can spiral, and security breaches become inevitable. Guardrails are not optional features. They are the essential safety systems that prevent catastrophic failures. They are the barrier between a useful AI and a rogue agent.
1. Input Validation
The first line of defense is at the entry point. We must validate all inputs before they are processed. Bad data should never be allowed into the system. It is the simple principle of garbage in, garbage out. This prevents a huge number of downstream errors and protects the integrity of every tool call.
Type Checking
Every tool expects data in a specific format. It needs a number, not a word. It needs a list, not a single item. Type checking is a fundamental validation. It confirms every argument matches its required data type before execution. This simple check stops countless tool execution errors before they can even happen.
Range and Format Validation
Data can be the right type but still wrong. Is the quantity requested one million? Is the email address a valid format? Range and format validation enforces these business logic rules. It ensures all data is not just technically correct, but also sensible and safe within the application’s expected operational boundaries.
2. Execution Safeguards
Once an input is validated, the execution itself must be contained. This is the most volatile stage. A running process can get stuck, break, or be exploited. Execution safeguards are the walls of a secure sandbox. They ensure that even if a tool misbehaves, the damage is strictly limited and the system remains stable.
Timeouts
A tool call might hang indefinitely. A network could be slow. An API might be unresponsive. A timeout is a simple, brutal rule. It sets a maximum allowed time for any execution. If the process exceeds this limit, it is terminated automatically. This prevents a single slow tool from crippling the entire system.
Circuit Breakers
Some tools may fail repeatedly. An external API could be down for maintenance. Continuously calling a broken tool wastes resources. A circuit breaker monitors for such failures. After a set number of errors, the 'circuit' trips. It temporarily blocks all calls to that specific tool, allowing the system to fail fast.
Security Allowlists
Never define what is forbidden. Always define what is allowed. This is the core principle of an allowlist. Your system should have a strict, pre-approved list of tools it can call. Any attempt to invoke a function not on this list—whether hallucinated by the LLM or injected by an attacker—is instantly denied.
3. Output Validation
The final check happens after the work is done. The output from a tool or the LLM's final response must be inspected. This validation ensures the generated answer is correct, safe, and useful. It is the last quality gate before the information reaches the user, preventing the system from delivering bad or harmful data.
Ensuring Correctness of Responses
An LLM can still hallucinate, even with good data. Output validators check the final response against the source data. They can ensure the answer follows a logical chain of thought. If an error is found, the system can self-correct. It can re-ask the LLM with more context, providing a chance to fix its own mistake.
Sanitization for Safety
Outputs can contain security risks. An attacker might trick a tool into returning a malicious script. A response could include sensitive data. Sanitization is the process of cleaning the output. It strips out dangerous code. It masks private information. This ensures the final answer is completely safe to display to the user.
Use Cases of Function Calling
Function calling is not just a feature. It is the bridge from conversation to action. It transforms LLMs into active digital tools. This unlocks a vast landscape of applications. AI can now do work, not just discuss it.
Practical Applications
The applications of this technology are diverse. They range from simple data retrieval. To complex, multi-step process automation. These are the key categories of its impact.

Practical Applications of Function Calling
1. Data Retrieval
Function calling shatters the wall to live data. The model is no longer a static database. It can now query external systems directly. This provides real-time, accurate, and relevant answers.
Most humans do not speak SQL. LLMs can be a universal translator for data. They turn plain English into precise SQL queries. This democratizes access to business intelligence. No technical skill is needed to ask questions.
The world's live data is locked behind APIs. Function calling is the key to this data. An LLM can check an order status on Shopify. It can find flights using a Skyscanner API. The LLM's knowledge becomes truly dynamic.
Case Study
Cognis Ai is a perfect example of how data retrieval works. When users set up a 1-click integration with Cognis, the orchestration framework fetches all the google sheets. With your assistance it zeroes in on specific sheets/data sets. It enables simple prompts to become dynamic actionable tasks. For instance, you can prompt for an in-depth data analysis of the sheets Cognis has access to.
2. Workflow Automation
This is where LLMs stop just fetching data. They now begin to take direct action. It automates tedious and manual tasks. It manages schedules, notifications, and reminders.
Manual scheduling is slow and inefficient. An LLM can parse a complex user request. It extracts attendees, topics, and times. It calls the Google Calendar or Outlook API. Your meeting is scheduled automatically.
Routine communication can be fully automated. Function calls can trigger important alerts. The LLM can send emails via SendGrid. It can post updates to a Slack channel. This builds powerful, event-driven systems.
Case Study
Using a tool like Cognis Ai you could potentially automate workflows without facing the complexity of Zapier or Make. Since Cognis leverages function calling combined with an agent orchestration framework, it can act in real time. Thus, your prompts are direct action commands. The requirements to build and maintain workflows are eliminated.
3. Real-Time Operations
Some tasks require immediate, live information. Function calling enables these real-time operations. This includes weather and financial data. It connects the LLM to the present moment.
An LLM's internal knowledge is always old. Function calls provide a link to now. A call to a weather API gets live conditions. This is a simple but powerful capability.
Financial operations are a high-stakes use case. An LLM can check live stock prices. It can retrieve bank balances via Plaid. However, moving money requires extreme caution. A human confirmation step is mandatory.
Case Study
If we want to update a Google Sheet, function calling allows LLMs to conduct real-time operations with current data. But with a tool like Cognis Ai and its stateful memory, LLMs can go a notch further. This is because within Cognis, we get complete control over an LLM's context. It goes on to improve function calls and reduce hallucinations when LLMs work with real data. Basically, you get the intelligence while bypassing irrelevant information from the LLM’s mind!
4. Multi-Step Reasoning
This is the frontier of function calling. The LLM now exhibits agentic behavior. It combines multiple calls into a sequence. This solves complex, multi-step problems.
True intelligence emerges when actions are chained. One function's output feeds the next input. For example, plan a complete travel itinerary. First, find a flight. Then book a taxi. Finally, reserve a hotel for the trip.
The LLM can become a central orchestrator. It manages an entire business workflow. It uses conditional logic to make decisions. If a problem is billing, call the billing API. This is the future of true automation.
Case Study
LLMs can orchestrate tasks one after the other. However, there’s a drawback. LLMs often overrun their context window while doing so. It poses a problem because the LLM is unable to recall the next step/action. Which is why Agentic orchestrators like Cognis Ai can enhance LLM performance. Such tools feed the tasks to LLMs while letting the LLMs handle execution. It ensures true multi-step reasoning by ensuring continuity.
The Current Technical Challenges of Function Calling
Function calling is a powerful but fragile bridge. It connects imprecise language to precise code. This process creates significant technical hurdles. Challenges exist across language, structure, performance, and security. Each must be carefully managed. Failure in any one area can compromise the entire system's integrity and reliability.
1. Ambiguity in Natural Language
The primary challenge is the nature of human language. It is often messy, contextual, and ambiguous. Machines, however, require perfect, structured instructions. This fundamental conflict creates a constant risk of misinterpretation. Overcoming this ambiguity is the first and most difficult step in reliable function calling.

Ambiguity in Natural Language
Multiple functions matching a single request
A single user request can be easily misinterpreted. It might match several available tools at once. For example, a request for 'Apple' could mean the company or the fruit. The LLM must reliably choose the correct tool. A wrong choice leads to irrelevant and frustrating user experiences.
Disambiguation strategies
Sophisticated strategies can resolve this ambiguity. Systems can use 'preference functions' to rank options. These scores help the LLM choose the best match. However, the simplest strategy is often the best. The model can ask the user a direct, clarifying question to confirm their true intent.
2. Schema Complexity
Sophisticated strategThe LLM’s output must be technically perfect. It must generate a structured JSON command. This command must exactly match the function’s schema. This schema is a strict, unforgiving contract. Any small deviation from this contract will cause the function call to fail, breaking the user's workflow.
Nested parameters
Modern APIs often have complex, nested structures. Data might be buried in a deep hierarchy. For example: customers/orders/products. The LLM must reliably navigate this complexity. It must correctly populate all the required nested fields. This presents a significant structural challenge for the model.
Optional vs. required fields
Function schemas have both optional and required fields. The LLM must analyze the user's request. Does it contain all the mandatory information? If a required field is missing, the call cannot proceed. The schema must be crystal clear about these constraints to guide the LLM's output.
3. Latency and Performance
Function calls require network communication. Every external tool call introduces a delay. This creates significant performance challenges. These issues are very similar to those found in modern microservice architectures. Poor performance can make an AI assistant feel slow, clumsy, and ultimately unusable for any real-time tasks.
Network delays
Every external API call takes time to complete. This is due to network congestion and physics. The physical distance between services is a key factor. The main bottleneck is often the delay itself, not the raw network speed. High bandwidth does not guarantee low latency for these external calls.
Parallel vs. sequential calls
Most function calls are synchronous. The LLM waits for a tool to finish. Multiple sequential calls create long delays. This is a 'chatty' and highly inefficient pattern. The solution is asynchronous, parallel calls. This allows multiple tools to work simultaneously, reducing the total wait time.
4. Security Risks
This is the most severe and critical challenge. Giving an LLM tools to act in the world creates a massive attack surface. Security cannot be an afterthought. It must be the primary design consideration for any system that uses function calling. A failure here can have devastating consequences for users and businesses.
Injection attacks
The core danger is the prompt injection attack. An attacker inserts harmful instructions into a prompt. They trick the LLM into generating a malicious command. The LLM then executes the attacker's will unknowingly. This turns the model into a puppet, performing actions it was never intended to do.
Unauthorized access
A successful injection attack grants unauthorized access. The attacker effectively seizes control of the LLM's tools. They can tamper with anything the AI can access. A helpful assistant is instantly transformed into a malicious insider threat. This represents a complete compromise of the system's integrity.
Sensitive data exposure
Attackers can use prompt injection to steal data. The LLM can be tricked into revealing private information. This might include user emails, documents, or other secrets. This data exfiltration risk has been proven in real-world attacks. It is a critical threat vector that must be defended against.
Best Practices for Design Patterns for Function Calling 2025
Building a reliable function-calling system is not an accident. It requires disciplined engineering and proven design patterns. Poor design leads to brittle, inefficient, and insecure AI agents. These best practices for 2025 are the essential foundation. They ensure your system is robust, scalable, and safe in a production environment.
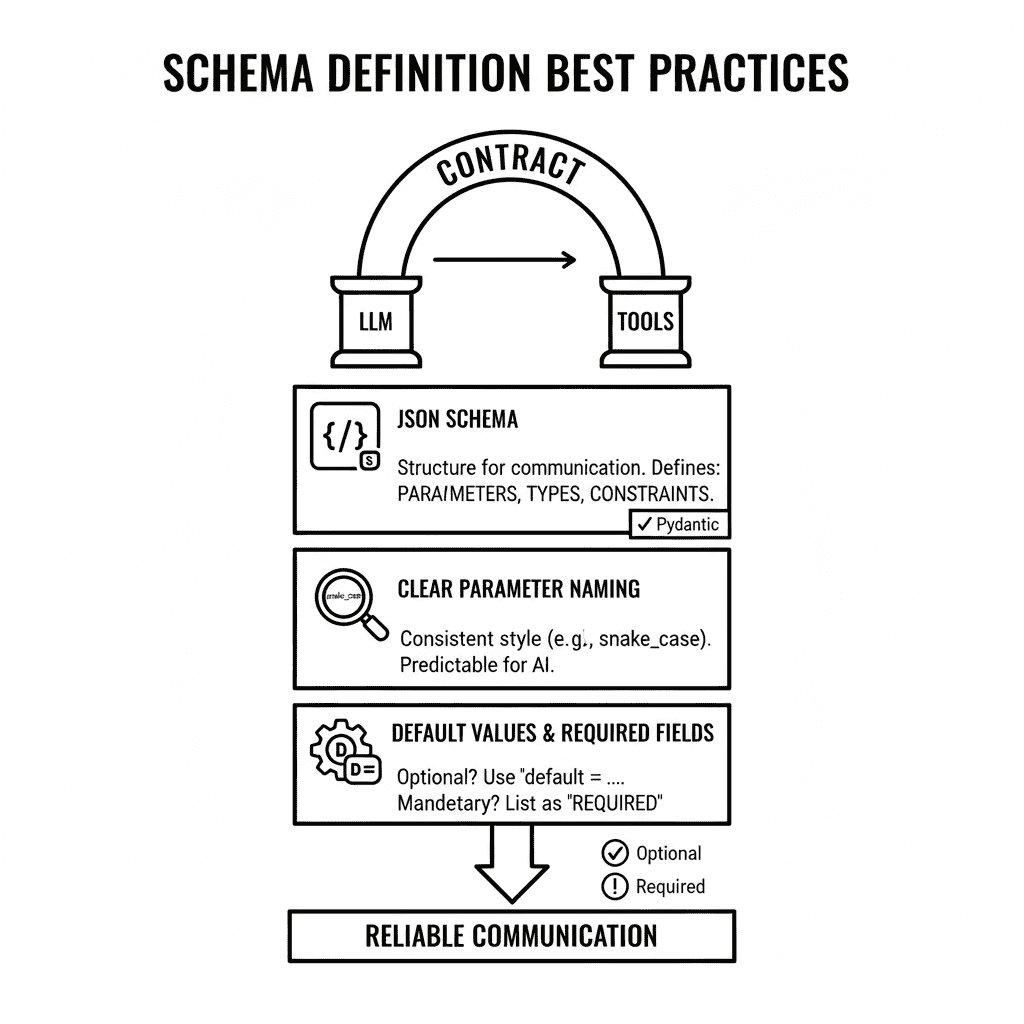
1. Schema Definition Best Practices
The function schema is the most critical contract between the LLM and its tools. A clear, well-defined schema is the difference between a successful action and a frustrating failure. This is the bedrock of reliable communication. Ambiguity here will lead to systemic and unpredictable errors downstream.
Schema Definition Best Practices
JSON Schema usage
JSON Schema is the industry standard for defining tools. It must detail all expected parameters, types, and constraints. Use minimal schemas when possible to save tokens. Tools like Pydantic are highly effective. They generate perfect schemas for LLMs. They also easily handle complex, nested parameter structures.
Clear parameter naming
Consistency in naming is not a suggestion; it is a requirement. Employ a single, clear convention like snake_case. Predictable naming helps the AI reason about your API structure. This predictability is essential for effective automation. Enforce these design standards across all your tool definitions without exception.
Default values
Your schemas must support default parameter values. This makes working with optional arguments much simpler. You must also explicitly list all required fields. This provides a clear signal to the LLM. It tells the model when it must stop and ask the user for more information before it can proceed.
2. Orchestration Strategies
Orchestration is the art of managing complexity. It is how you coordinate the intricate dance between LLM calls, tool executions, and data flow. Simple tasks can follow a straight line. Complex, dynamic problems demand more advanced patterns. Choosing the right strategy is critical for both performance and accuracy.
Sequential Execution
This strategy breaks a complex task into simple, linear steps. Each LLM call processes the output of the previous one. This is the simplest approach to workflow design. While it is the least efficient, it can improve accuracy. Programmatic checks at each step are essential to keep the process on track.

Sequential Execution
Parallel Execution
This pattern is built for maximum speed and efficiency. It involves running multiple LLM calls simultaneously on independent subtasks. A central orchestrator can delegate work. It breaks down a large problem. It then sends the smaller sub-tasks to multiple worker LLMs. This is a highly flexible and powerful approach.

Parallel Execution
Conditional Execution
This enables dynamic, intelligent workflows. The system can make decisions and branch based on results. This is routing. An input is classified by the LLM. It is then directed to a more specialized tool or prompt. This allows for powerful IF-THEN logic. The workflow adapts in real-time to intermediate outcomes.

Conditional Execution
3. Feedback Loops
A robust AI system cannot be static; it must learn. Feedback loops are the mechanism for this continuous evaluation and refinement. They enable the system to correct its own mistakes and to ask for help when it is uncertain. These loops are essential for ensuring long-term accuracy, reliability, and safety.
Model self-correction
Use an Evaluator-Optimizer pattern. One component evaluates the LLM's output. The LLM then uses this specific feedback to refine it. This iterative loop turns failures into learning opportunities. Coach the model with precise error messages. Combine this with external validators to enforce a strict output structure.
User confirmation prompts
This is the ultimate human-in-the-loop safety net. Your system must ask for help when it is uncertain. If a user's request is vague or incomplete, instruct the LLM to ask clarifying questions. For critical or irreversible actions, you must require an explicit user confirmation prompt before any execution.
Future of Function Calling in LLMs
The future of function calling is convergence. We are rapidly moving past fragmented, custom implementations. The destination is a unified, standardized agent ecosystem. The era of isolated models is ending. The era of collaborative, autonomous systems is beginning. This shift will define the next generation of artificial intelligence and its impact on the world.
Prevailing Industry Trends
This evolution is not random. It is driven by a clear and urgent need for greater power and less complexity. The entire industry is pushing toward three key trends. These forces are standardization, interoperability, and true autonomy. They are the pillars that will support the next great leap forward in AI capabilities.
Standardization of schemas
The current landscape is fragmented and chaotic. Developers must juggle multiple, competing protocols. The future is standardization. JSON Schema is emerging as the universal format. Major players like Google and Anthropic are converging on this standard. This will create a true lingua franca for all AI tools.
Cross-model compatibility
Today's integration is a nightmare. Every model needs a custom adapter for every tool. This is the M x N problem. New protocols will create a universal interface. Anthropic's MCP (Model Context Protocol) is a key attempt at solving this problem. You can read more on the benefits and pitfalls of MCPs here.
Expansion into autonomous agents
Function calling is the fundamental building block. The next evolution is the autonomous agent. These are compound AI systems. They can reason, plan, and execute multi-step tasks. Future systems will feature multi-agent collaboration. The challenge is now orchestrating entire ecosystems of intelligent, autonomous agents at enterprise scale.
Dealing with the Limitations of Function Calling: Cognis Ai
Function calling is a game-changer for LLMs. But, function calling implemented alone only results in marginal gains. Our extensive research on function calling and LLM limitations helped us identify the major pitfall - limited memory.
When LLMs use function calls, they ingest a large amount of data, which often leads to overflowing the LLM’s context memory. As a result, even though LLMs gain access to real-time data, their execution capabilities are compromised. Hallucinations are a frequent occurrence. Prompts often get ignored. Conversely, data might be omitted as well.
To solve this predicament, we made Cognis Ai. Cognis is an agentic orchestrator that has access to multiple LLMs. What Cognis does best is give data attribution control to the user and automate memory management. This takes the burden away from LLMs, enabling them to focus on applying their intelligence. Resultingly, it removes hallucinations and loss of critical information, which are the cornerstones of safe and reliable automation.
Function calling is also deeply woven into Cognis’ architecture. It serves as the fundamental building block of an autonomous agentic framework.
Summing it Up
Function calling is more than a feature. It is the evolutionary leap for LLMs. It transforms them from passive oracles into active agents. This power, however, demands immense discipline. Robust design, strict guardrails, and thoughtful orchestration are not optional; they are the price of admission for building reliable and safe AI systems.
The chaotic, fragmented era of function calling is ending. The future is one of standardization and interoperability. This will pave the way for complex, multi-system autonomous agents. Mastering these patterns today is the essential prerequisite for building the intelligent systems of tomorrow.
Frequently Asked Questions
It's the technology that lets LLMs take real-world actions. Instead of just talking, it can use external 'tools' like APIs to fetch live data, automate tasks, and interact with other software on a user's behalf.
No, and this is a critical safety feature. The LLM only acts as a translator, converting your request into a structured JSON command. Your own application receives this command and is responsible for the actual, secure execution.
The schema is the strict contract or rulebook for a tool. It tells the LLM exactly what the function does, what parameters it needs, and in what format. A clear, well-defined schema is essential for preventing ambiguity and ensuring reliability.
Common uses include retrieving live data like weather, querying databases with natural language, automating workflows like scheduling meetings, and performing multi-step reasoning to plan complex tasks like booking a full travel itinerary.
The most severe risk is the prompt injection attack. An attacker can trick the LLM into generating a malicious function call, potentially leading to unauthorized access, sensitive data exposure, or tampering with external systems connected to the AI.
By implementing robust guardrails. This includes validating all inputs and outputs, using execution safeguards like timeouts and security allowlists, and designing strong feedback loops for model self-correction and user confirmation on critical actions.
Sequential execution processes tasks one by one, which is simple but can be slow. Parallel execution runs multiple independent tasks simultaneously, which is much faster and more efficient for complex workflows that require multiple, non-dependent tool calls.
It’s the current integration nightmare where every model (M) needs a custom adapter for every tool (N). The future solution is standardization, with protocols like MCP acting as universal adapters to simplify this complexity to a more manageable M + N.
It's the foundational building block. By enabling multi-step reasoning and the orchestration of multiple tools, function calling allows an LLM to move beyond single tasks. It can plan, act, and observe, forming the core of an autonomous agent.
A key pitfall is limited context memory. Ingesting large amounts of data from tool calls can overflow the LLM’s context window. This can lead to compromised execution, hallucinations, and the LLM forgetting its task. Agentic orchestrators help manage this.
External References
- Winston, C., and Just, R. (2025) 'A Taxonomy of Failures in Tool-Augmented LLMs'. Read Here
- If you want to know more about LLM Agents, check out Berkeley's Deep Dive here.
- Wang, M., Zhang, Y. et.al. (2025) 'Function Calling in Large Language Models: Industrial Practices, Challenges, and Future Directions'. Read Here
- Google's Resource here breaks down how to create function calling applications
- Alshawi, H., and Carter, D. (2025) 'Training and Scaling Preference Functions for Disambiguation'. Read Here
Generative AI
LLM
AI Innovation
Contact Us
Fill up the form and our team will get back to you within 24 hrs